페이스북으로 유명한 메타가 텍스트(문자), 이미지, 오디오 등 6가지 유형의 정보를 묶어 학습할 수 있는 새로운 오픈소스 AI 모델을 공개했습니다. 메타의 AI모델은 대규모 언어 모델 ‘라마(LLaMA)’, 이미지 분할 모델 ‘SAM(Segment Anything Model)’이 있었는데요. 최근에 공개된 멀티모달 AI 모델 '이미지바인드'는 텍스트, 이미지, 비디오, 오디오, 심도(3D), 열화상(적외선), 동작과 위치를 계산하는 관성 측정 장치(IMU) 센서 데이터 등 총 6가지 다른 유형의 데이터를 동시에 학습하여 처리할 수 있는 AI 모델입니다. 더불어 이것을 오픈소스로 공개했다는 점에서 화제입니다.
일반적으로 여러 유형의 데이터를 처리하는 멀티모달 모델은 각각의 데이터를 별도의 임베딩(embedding)에 저장하는데요. 그러나 '이미지바인드' 모델은 여러 가지 데이터를 하나의 임베딩에 함께 저장하여 처리하기 때문에 이전 모델보다 높은 처리 능력을 가지고 있다는 점에서 차별화되고 있습니다.
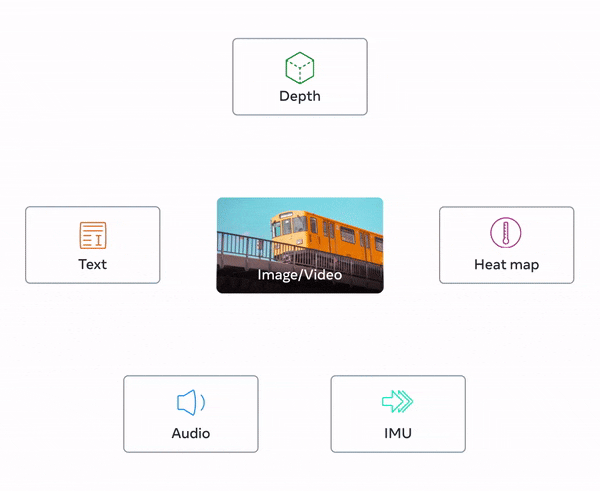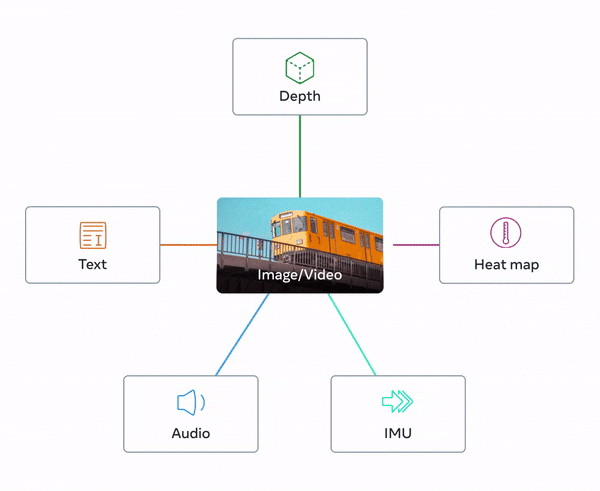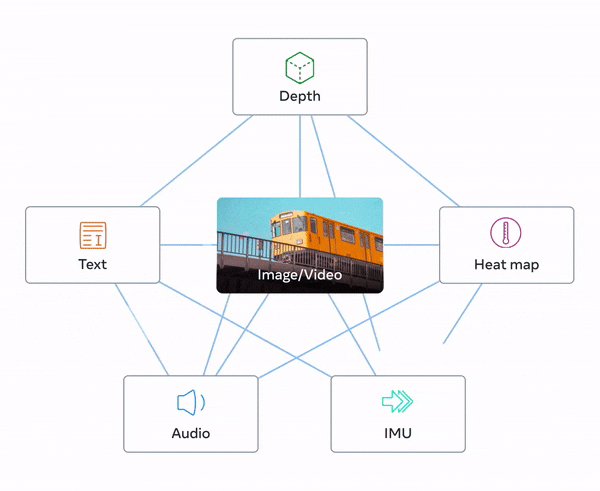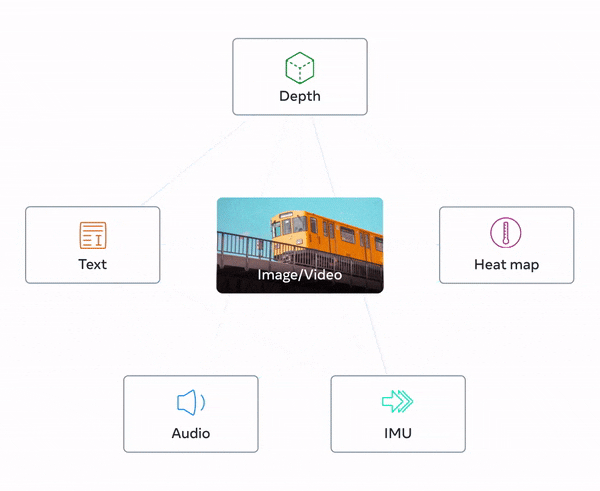
또한, 이 모델은 무료로 제공되는 오픈소스 기반 모델로서, 다양한 연구원들과 함께 연구하고 개발할 수 있다는 점에서 관심을 받고 있습니다. 이러한 멀티모달 AI 모델은 각종 산업과 학계에서 활용될 예정이며, 높은 처리 능력과 다양한 데이터 처리 기능을 통해 대부분의 분야에서 적용 가능할 것으로 기대됩니다.
이미지바인드 모델은 데이터를 별도로 저장하지 않고, 여러 유형의 데이터를 결합하여 단일 임베딩으로 보관하는 모델입니다. 이를 통해 복잡한 컴퓨팅 작업을 더 쉽게 지원할 수 있습니다. 또한 이 모델은 여러 유형의 데이터를 한 번에 분석할 수 있기 때문에, 스케치, 텍스트 설명 등으로 부터 자동차 이미지를 생성할 수 있습니다.
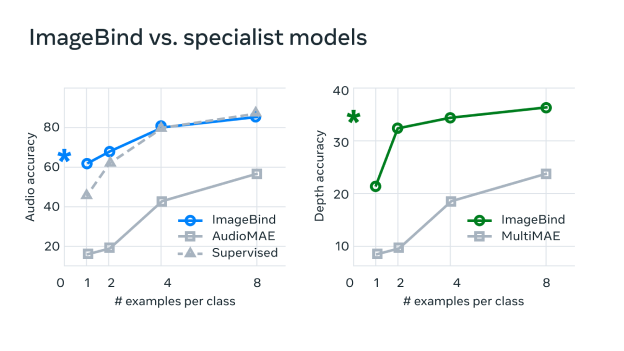
이미지바인드 모델은 인간의 다양한 감각에서 정보를 수집하고, 이를 동시에 전반적으로 처리할 수 있는 방법인 인간의 능력에 대한 접근 방법을 취합니다. 이를 통해 사진 속 물체가 소리를 내고, 3D처럼 보이는지, 얼마나 따뜻하고 추운지, 어떻게 움직이는지와 같은 전반적인 이해를 기계에 제공할 수 있습니다.

이미지바인드 모델은 이미지나 비디오를 입력으로 사용하여 관련된 오디오를 검색하거나, 오디오를 입력하여 관련된 이미지를 검색하거나, 텍스트로 관련된 이미지나 오디오 클립을 검색할 수 있습니다. 또한, 이미지바인드를 생성 AI 모델과 결합하면 오디오에서 이미지를 생성하는 것도 가능합니다.
메타는 이번 연구를 통해, 기계가 다양한 형태의 정보를 동시에 전반적으로 직접 학습할 수 있는 인간의 능력에 더 가까워질 수 있다고 강조하고 있습니다. 또한, 향후 다양한 감각, 예를 들어 촉각, 화법, 후각, 뇌 fMRI(기능적 자기공명영상) 신호와 같은 것들을 연결하면 인간 중심 AI 모델이 가능해질 것이라고 기대하고 있습니다.
'과학 뉴스 > 로봇,AI 뉴스' 카테고리의 다른 글
| 구글의 대화형 AI '바드', 구글 검색이 획기적으로 변경된다 (0) | 2023.05.15 |
|---|---|
| AI, 안과 질환 진단에서 전문의와 동등한 성능 발휘 (0) | 2023.05.11 |
| 군 임무에 사용될 사족보행 로봇? 2023 국방기술포럼의 이야기 (0) | 2023.05.10 |
| 딥엘 한국 지원 - 독일 인공지능 기계번역기 국내 시장 공략 (0) | 2023.05.10 |
| 뤼튼테크놀로지스, 대화와 이미지 생성 서비스 무료 제공 (0) | 2023.05.05 |




댓글